
Searchable PDFs refer to portable document format files containing actual text characters behind the images rather than just pictures of text incapable of searching.
Through optical character recognition (OCR) technology, scanned documents or image-based PDFs transform into text-based PDFs that recognize words for searching, copying, editing and other functions. Creating searchable PDFs only takes a few clicks using capable software.
In our blog post, you’ll learn how OCR technology converts files, tools to enable text recognition, and best practices for managing search-optimized PDFs.
Benefits of Searchable PDFs
Improved searchability
The most immediate benefit searchable PDFs provide is precisely the ability to search documents for keywords and phrases to instantly pinpoint relevant passages, statistics, names and other textual elements without painstakingly skimming through pages manually.
The text recognition applied to formerly images-only files massively improves discovery and navigation.
Enhanced user experience
In addition to searchability, recognizing text characters within PDFs enhances overall usability by finally allowing highlighting, commenting, editing, copying and pasting passages of interest. Assistive reader tools also leverage recognized text for improved accessibility like read-aloud narration and AI-based translation into different languages.
Accessibility for visually impaired individuals
For those relying on screen readers to translate visual documents into audio, OCR-enabled PDFs allow assistive software finally making sense of previously image-based content now transformed into actual words driving accurate narration and translation. Such accessibility opens materials to wider audiences.
Methods to Make a Searchable PDF
Using Optical Character Recognition (OCR) software
Explanation of OCR technology
Optical character recognition refers to advanced AI-powered software algorithms capable of detecting words and characters within image and scanned document files like JPEGs and PDFs to extract and recognize actual text. OCR software processes files identifying shapes resembling letters, numbers and common glyphs, determining patterns of characters forming actual words for machine reading.
Step-by-step guide to using OCR software
Most OCR software like Adobe Acrobat follow a straightforward workflow for recognizing text within PDFs:
- Open the desired image PDF in the OCR tool
- Click menu option to recognize text – usually “Recognize Text”
- Allow the OCR engine a few seconds per page for processing
- All text now becomes highlighted showing selection and searchability enabled
- Save out final PDF to retain OCR corrections
Converting scanned documents to searchable PDFs
Tools and software for scanning
To handle paper documents, a scanner converts physical sheets into digital PDF files. Top options like those from Fujitsu, Canon imageFORMULA and Epson WorkForce boast advanced feeds and speeds to digitize stacks rapidly into image PDFs awaiting OCR for searchability.
Converting scanned images to text
Instead of manual OCR software, automated chat pdf solutions like PopAi use cutting-edge machine learning to transform scanned PDF images into perfectly searchable, editable documents batch-wide without human intervention. Users simply submit the scanned PDF files needing OCR conversion to PopAi’s cloud platform for advanced AI text recognition.
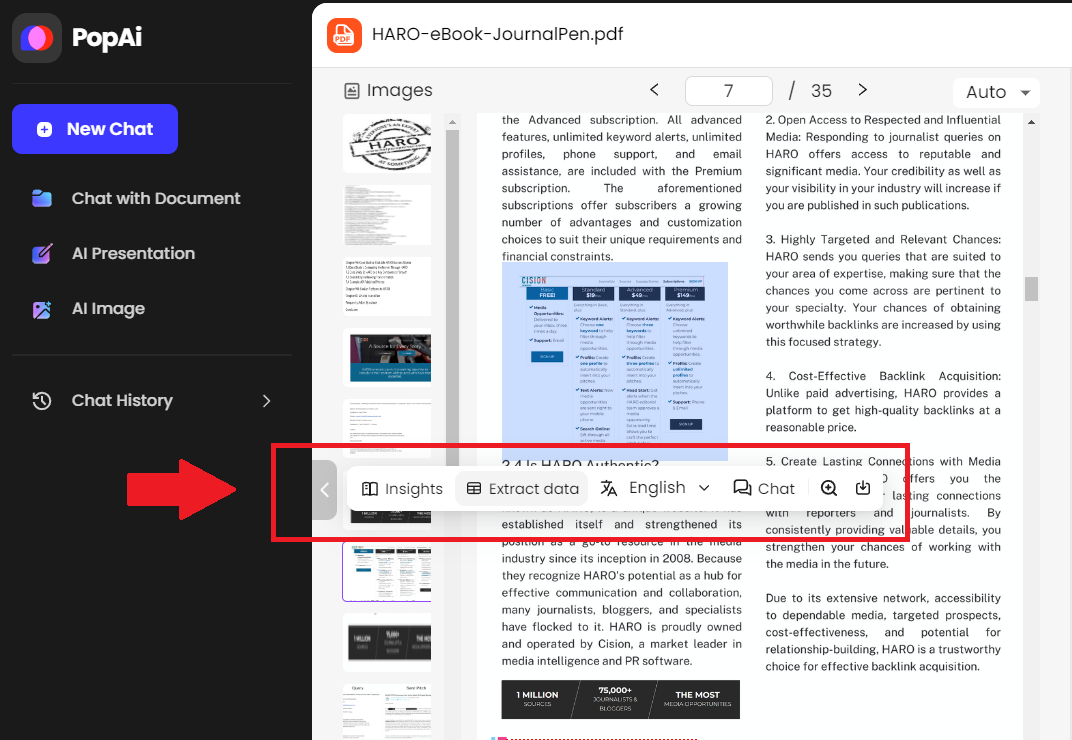
Manual editing for text recognition
Best practices for manual editing
Inevitably some characters misinterpret during OCR scanning. Carefully proofread files post-conversion, manually correcting any indistinct letters the engine mistranslated, like lower case “L” becoming the number “1” for example. Expect to tweak proper nouns like names and technical vocabulary not appearing in OCR dictionaries.
Importance of proofreading
Like any automated process, double checking OCR corrections manually ensures no false text appears altering original meanings before sharing files containing sensitive data, lest legal materials get compromised. While tedious for large documents, proofing provides quality assurance.
Tools and Software for Creating Searchable PDFs
Adobe Acrobat Pro
Features for creating searchable PDFs
As the industry PDF leader, Adobe Acrobat Pro serves as a versatile OCR engine for unlocking searchability including custom font training for accuracy, multilingual recognition and automated tagging of elements like headings and images for accessibility during conversions.
Steps to convert a PDF to searchable text
Within the Acrobat interface, open the desired image-based PDF, select the “Recognize Text” option from the right-side menu then wait for processing to complete. Optionally train on specific areas getting misinterpreted. Finally save the searchable PDF.
Abbyy FineReader
Overview of Abbyy FineReader
FineReader stands among the most accurate OCR solutions available, wielding AI-based optical character recognition technology for converting image and PDF files into searchable, editable documents through cutting-edge machine learning trained on billions of data points for precision results.
Steps to convert scanned documents to searchable PDFs
- Install FineReader desktop application
- Open program and import desired image PDF
- Click “Read Document” button to initiate OCR scan
- Text highlights as recognized while processing pages
- Upon completion, inspect any areas needing correction
- Finally export PDF retaining recognized text
Other tools and software options
Comparison of different tools
Many capable OCR options exist beyond Acrobat and FineReader including Foxit PhantomPDF, Readiris Pro, Microsoft Office Lens, Scanbot and CamScanner for reliably extracting text from images and scanned PDFs using machine learning algorithms with solid accuracy rates. Most operate similarly workflow-wise.
Pros and cons of each tool
Comparing OCR tools shows tradeoffs around processing speeds, language/font support and accuracy percentages based on training data quantity. Top solutions score 90%+ accuracy given optimal input quality materials and reasonable fonts. Pricing varies widely from free mobile apps to enterprise platforms costing hundreds annually.
Best Practices for Optimizing Searchable PDFs
Naming conventions for PDF files
To aid search engine discovery after publishing searchable PDFs online, ensure filenames and titles contain relevant keywords and descriptive terminology related to the document’s core subject matter rather than generic names like “brochure” or “guide” which offer little contextual relevance.
Adding metadata for better searchability
Further enhances PDF findability by populating metadata fields like Title, Author, Description and Keywords which search engines index directly to better understand document contents without needing actual PDF crawling.
Compressing PDF files for faster loading times
To ensure lightning-fast page loading for user experience and SEO technical factors, use an online PDF compressor to condense OCR-enabled PDF file sizes without affecting image quality for leaner storage and data transfers keeping readers engaged. Eliminate bloated files hampering performance.
Conclusion
Unlocking millions of scanned materials safely tucked away within image PDFs, optical character recognition AI empowers users finally searching, editing and manipulating previously restricted content for improved accessibility and discovery.
Through OCR tools leveraging machine learning to modernize archives, previously muted materials find new voice driving research and visibility further extending the powerful document digitization movement making information available to more people in more ways over time.


